
Home
A Data Structure is a way to organize and store data in a computer so it can be used easily.
For example, a program may store:
numbers,names, messages, images
If data is not organized, the computer cannot work with it efficiently.
So we use data structures to store and manage data properly.
Data structures help us to:
1. Store data efficiently
2. Find data quickly
3. Update data easily
4. Process large amounts of data
5. Without data structures, programs would become slow and difficult to manage.
6. Big systems like social media, banking apps, and search engines all use data structures.
There are many kinds of data structures. The most common ones are:
Basic Data Structures
Array
Linked List
Stack
Queue
Advanced Data Structures
Tree
Graph
Hash Table
Heap
We will learn each one step by step with examples and code.
An Array is a data structure used to store multiple values in one variable.
Instead of creating many variables, we store everything inside one array.
Example:
let numbers = [10, 20, 30, 40];
Here the array stores 4 values.
Each value in an array has a position number called an index.
Important rule:
Array index always starts from 0
Example:
let numbers = [10, 20, 30, 40];
Index Value
0 - 10
1 - 20
2 - 30
3 - 40
Accessing values:
numbers[0] → 10
numbers[2] → 30
Common things we do with arrays:
1 Access value
numbers[1]
2 Add value
numbers.push(50)
3 Remove value
numbers.pop()
4 Change value
numbers[0] = 100
Arrays are very fast for accessing data using index.
Time Complexity means:
How much time a program takes to run
We don’t measure time in seconds.
We measure how the time grows when input increases.
Example idea:
Small data → fast
Big data → slower
Time complexity helps us understand how efficient our code is.
We use something called Big O Notation to describe time complexity.
It looks like this:
O(1) → very fast (constant time)
O(n) → grows with input
O(n²) → slower (nested loops)
Example:
for(let i = 0; i < n; i++){
console.log(i);
}
This is O(n) because it runs n times.
Here are the most important ones:
⚡ O(1) – Constant
Always same speed
Example:
numbers[0]
🚶 O(n) – Linear
Depends on input size
Example:
for(let i = 0; i < n; i++){}
🐢 O(n²) – Quadratic
Very slow for big data
Example:
for(let i = 0; i < n; i++){
for(let j = 0; j < n; j++){}
}
💡 Simple idea:
O(1) → best
O(n) → okay
O(n²) → avoid if possible
A Linked List is a data structure where:
👉 Each item (node) is connected to the next item
It is like a chain:
[10] → [20] → [30] → [40]
Each part is called a node.
Structure of a Node
Each node has 2 parts:
1 Data → the value (like 10, 20)
2 Next → a link to the next node
Example:
let node = {
data: 10,
next: null
}
Chain example:
10 → 20 → 30 → null
👉 null means end of list
Array
Fixed size (or harder to change)
Fast access using index
Example: arr[2]
Linked List
Dynamic size (can grow easily)
No index
Must go step by step to find data
💡 Simple idea:
Array = fast access
Linked List = flexible size
Traverse means:
👉 Go through all nodes one by one
Since there is no index, we must start from the beginning.
Example:
let current = head;
while(current !== null){
console.log(current.data);
current = current.next;
}
💡 This prints all values in the list.
👉 Insert at beginning
let newNode = {
data: 5,
next: head
};
head = newNode;
Now list becomes:
5 → 10 → 20 → 30
👉 Insert at end
let newNode = {
data: 50,
next: null
};
let current = head;
while(current.next !== null){
current = current.next;
}
current.next = newNode;
👉 Delete first node
head = head.next;
👉 Delete specific value
let current = head;
while(current.next !== null){
if(current.next.data === 20){
current.next = current.next.next;
break;
}
current = current.next;
}
💡 Simple idea:
Traverse → read data
Insert → add node
Delete → remove node
A Stack is a data structure that follows:
👉 LIFO (Last In, First Out)
Meaning:
The last item you add is the first one you remove
Example:
[10, 20, 30]
👉 30 will be removed first
1 Push (Add item)
stack.push(40)
Now:
[10, 20, 30, 40]
2 Pop (Remove item)
stack.pop()
Removes 40
3 Peek (See top item)
stack[stack.length - 1]
Shows last value without removing it
💡 Stack always works from the top
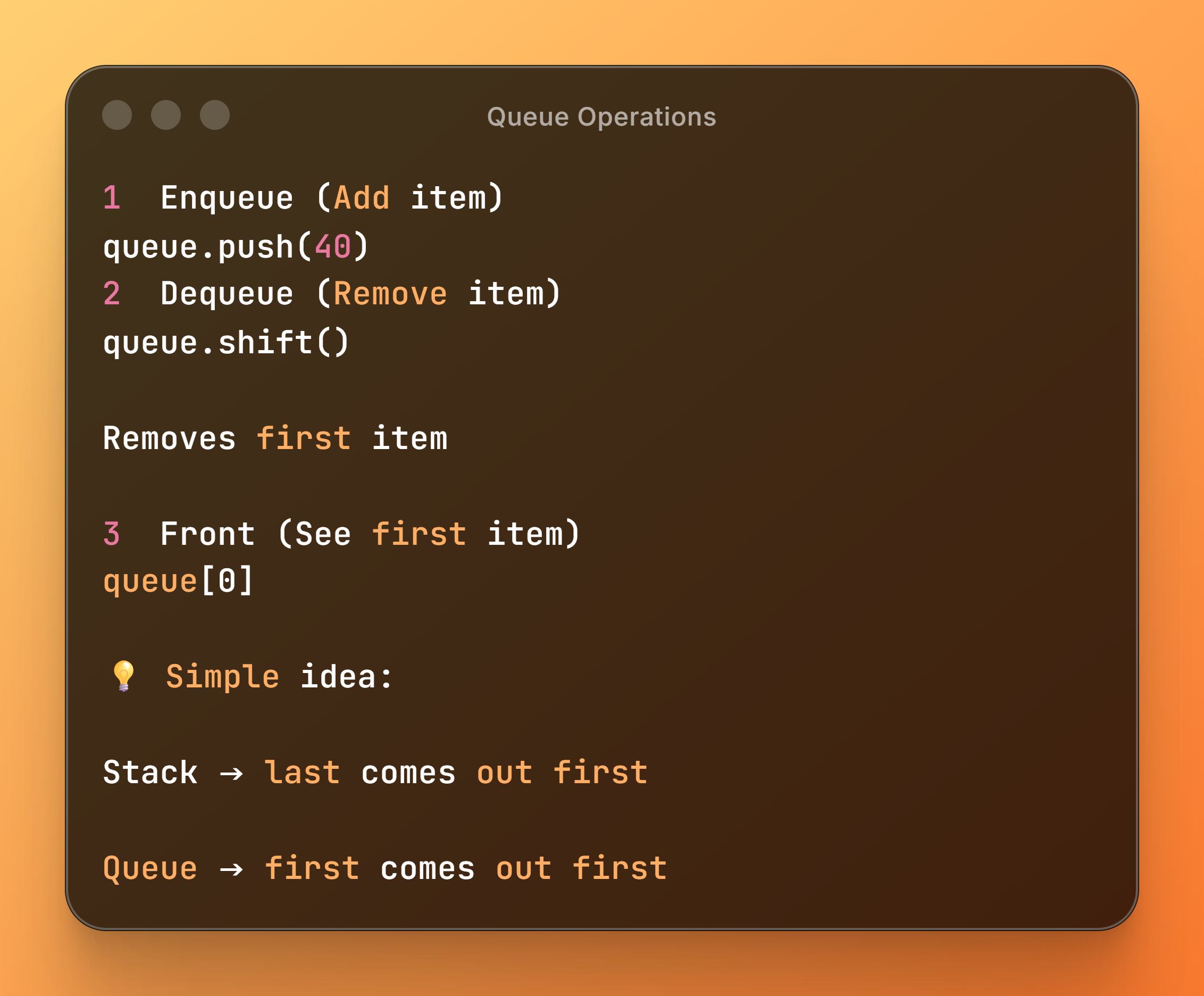
A Queue is a data structure that follows:
👉 FIFO (First In, First Out)
Meaning:
First item added is the first one removed
Example:
[10, 20, 30]
👉 10 will be removed first
1 Enqueue (Add item)
queue.push(40)
2 Dequeue (Remove item)
queue.shift()
Removes first item
3 Front (See first item)
queue[0]
💡 Simple idea:
Stack → last comes out first
Queue → first comes out first
A Tree is a data structure that looks like a hierarchy.
It starts from one top node and branches down.
Example:
10
/ \
20 30
/ \
40 50
Important Terms:
Root → top node (10)
Parent → node with children (20)
Child → node below (40, 50)
Leaf → node with no children (40, 50, 30)
💡 Trees are used in:
File systems
Databases
Searching
A Binary Tree is a tree where:
👉 Each node can have maximum 2 children
Left child
Right child
Example:
10
/ \
20 30
💡 Rule:
Each node → at most 2 children
A BST is a special binary tree with rules:
👉 Left side → smaller values
👉 Right side → bigger values
Example:
10
/ \
5 20
/ \ \
2 7 30
Why BST is powerful?
Because it makes searching very fast
👉 Like binary search
Traversal means:
👉 Visiting all nodes
Types:
1 Inorder (Left → Root → Right)
Left → Root → Right
2 Preorder (Root → Left → Right)
Root → Left → Right
3 Postorder (Left → Right → Root)
Left → Right → Root
💡 Traversal is used to:
Read data
Process trees
A Graph is a data structure used to show connections between things.
It has:
Nodes (Vertices) → points
Edges → connections between nodes
Example:
A — B
| |
C — D
💡 Real life examples:
Social networks
Maps (cities & roads)
Internet connections
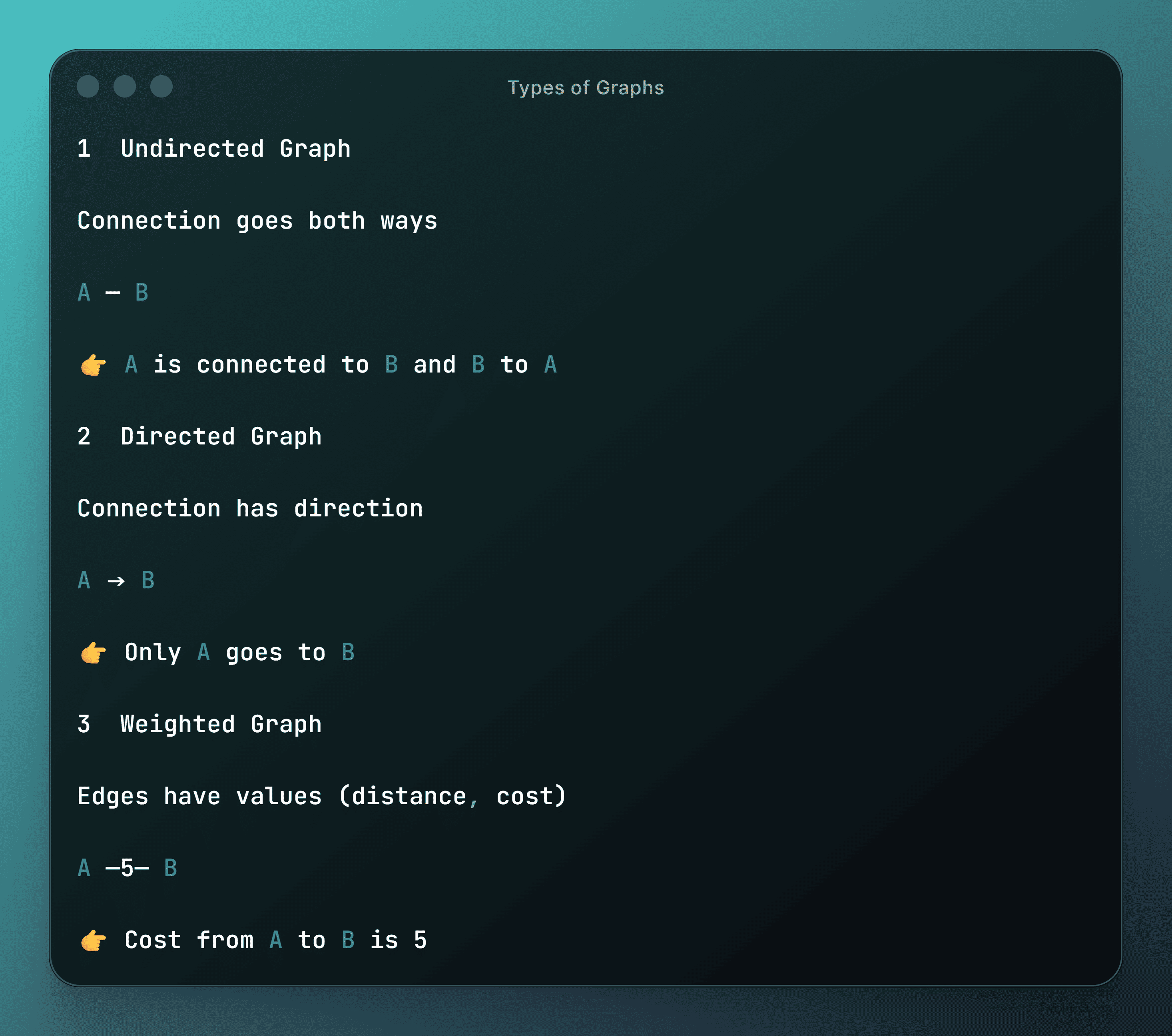
1 Undirected Graph
Connection goes both ways
A — B
👉 A is connected to B and B to A
2 Directed Graph
Connection has direction
A → B
👉 Only A goes to B
3 Weighted Graph
Edges have values (distance, cost)
A —5— B
👉 Cost from A to B is 5
Traversal means:
👉 Visiting all nodes
🔵 BFS (Breadth First Search)
Goes level by level
Uses Queue
Example flow:
A → B → C → D
🔴 DFS (Depth First Search)
Goes deep first
Uses Stack
Example flow:
A → B → D → C
💡 Simple idea:
BFS → wide (level)
DFS → deep
A Hash Table stores data in key-value pairs.
Example:
{
name: "Zohil",
age: 20
}
Why use Hash Table?
👉 Very fast access
data["name"] // very fast
💡 Used in:
Databases
Caching
APIs
A Heap is a special tree used for priority.
Types:
🔹 Min Heap
Smallest value on top
🔹 Max Heap
Largest value on top
Example (Min Heap):
5
/ \
10 20
💡 Used in:
Priority queues
Scheduling
Algorithms
Sorting means:
👉 Arranging data in order (small → big or big → small)
Example:
[5, 2, 9, 1] → [1, 2, 5, 9]
Common Sorting Types:
1 Bubble Sort
Compare and swap values
Simple but slow
👉 Time: O(n²)
2 Selection Sort
Find smallest and place it first
👉 Time: O(n²)
3 Quick Sort (Important)
Divide and sort
👉 Time: O(n log n) (fast)
💡 Simple idea:
Small data → any sort works
Big data → use Quick Sort
Searching means:
👉 Finding a value
1 Linear Search
Check one by one
for(let i = 0; i < arr.length; i++){
if(arr[i] === x) return i;
}
👉 Time: O(n)
2 Binary Search (Very Important)
👉 Works only on sorted array
Steps:
Check middle
Go left or right
👉 Time: O(log n) (very fast)
Recursion means:
👉 A function calling itself
Example:
function count(n){
if(n === 0) return;
console.log(n);
count(n - 1);
}
💡 Important:
Every recursion must have:
Base case (stop condition)
Recursive call
To become strong 💪 you must practice:
Examples:
Reverse array
Find max/min
Palindrome check
Stack/Queue problems
Tree traversal
👉 Practice = real learning
🛠 Mini Project Ideas:
Task Manager (use arrays + stack)
Contact list (use hash table)
Simple search system
Understand concepts (not memorize)
Practice coding daily
Focus on:
Arrays
Strings
Trees
Graphs
An Algorithm is:
👉 A step-by-step process to solve a problem
Example:
Problem: Make tea ☕
Algorithm:
1. Boil water
2. Add tea
3. Add sugar
4. Pour into cup
💡 In programming:
Algorithm = steps your code follows
Algorithms help you:
Solve problems correctly
Make programs faster ⚡
Handle big data easily
Write better code
👉 Same problem, different algorithm → different speed
👉 Data Structure = how data is stored
👉 Algorithm = how data is used
Example:
Array (data structure)
Searching in array (algorithm)
💡 Simple idea:
Data Structure = container
Algorithm = action
There are different types of algorithms based on how they solve problems:
🔹 1. Brute Force
👉 Try every possible solution
Example:
Check each number one by one
💡 Simple but slow
🔹 2. Divide and Conquer
👉 Break problem into smaller parts
Example:
Binary Search
Quick Sort
💡 Very fast and powerful
🔹 3. Greedy Algorithm
👉 Pick the best choice at each step
Example:
Choosing biggest profit first
💡 Fast but not always correct
🔹 4. Dynamic Programming (DP)
👉 Solve once, store result, reuse it
💡 Saves time, avoids repeating work
Efficiency means:
👉 How fast and how much memory an algorithm uses
We measure:
Time Complexity (speed)
Space Complexity (memory)
💡 Goal:
👉 Use less time + less memory
Every algorithm has:
👉 Input
Data given to algorithm
Example:
[1, 2, 3]
👉 Output
Result after processing
Example:
[3, 2, 1]
💡 Simple idea:
Input → Process → Output
Linear Search means:
👉 Check each element one by one until you find the target
Example:
[10, 20, 30, 40]
Find: 30
Steps:
Check 10 ❌
Check 20 ❌
Check 30 ✅ (found)
Code:
function linearSearch(arr, target){
for(let i = 0; i < arr.length; i++){
if(arr[i] === target){
return i;
}
}
return -1;
}
👉 Time: O(n)
Works only on sorted arrays
Example:
[10, 20, 30, 40, 50]
Find: 30
Steps:
Check middle → 30 ✅ found
Code:
function binarySearch(arr, target){
let left = 0;
let right = arr.length - 1;
while(left <= right){
let mid = Math.floor((left + right) / 2);
if(arr[mid] === target){
return mid;
}
else if(arr[mid] < target){
left = mid + 1;
}
else{
right = mid - 1;
}
}
return -1;
}
👉 Time: O(log n) (very fast)
👉 Compare and swap adjacent values
Example:
[5, 3, 2]
Steps:
5 ↔ 3 → [3,5,2]
5 ↔ 2 → [3,2,5]
3 ↔ 2 → [2,3,5]
Code:
function bubbleSort(arr){
for(let i = 0; i < arr.length; i++){
for(let j = 0; j < arr.length - i - 1; j++){
if(arr[j] > arr[j + 1]){
let temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
return arr;
}
👉 Time: O(n²) (slow)
💡 Simple idea:
Linear → check all
Binary → smart search
Bubble → simple sorting
👉 Idea:
Find the smallest value and put it at the beginning.
Example:
[5, 3, 2, 4]
Steps:
Smallest = 2 → swap with 5 → [2,3,5,4]
Next smallest = 3 → already correct
Next smallest = 4 → swap with 5 → [2,3,4,5]
Code:
function selectionSort(arr){
for(let i = 0; i < arr.length; i++){
let minIndex = i;
for(let j = i + 1; j < arr.length; j++){
if(arr[j] < arr[minIndex]){
minIndex = j;
}
}
let temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
return arr;
}
👉 Time: O(n²)
👉 Idea:
Pick one element and insert it in the correct position
Example:
[5, 3, 4]
Steps:
Take 3 → place before 5 → [3,5,4]
Take 4 → place between → [3,4,5]
Code:
function insertionSort(arr){
for(let i = 1; i < arr.length; i++){
let key = arr[i];
let j = i - 1;
while(j >= 0 && arr[j] > key){
arr[j + 1] = arr[j];
j--;
}
arr[j + 1] = key;
}
return arr;
}
👉 Time: O(n²) (but faster than bubble in practice)
👉 Uses Divide & Conquer
Steps:
Divide array into halves
Sort each half
Merge them
Example:
[5, 3, 2, 4]
→ [5,3] [2,4]
→ [3,5] [2,4]
→ [2,3,4,5]
Code:
function mergeSort(arr){
if(arr.length <= 1) return arr;
let mid = Math.floor(arr.length / 2);
let left = mergeSort(arr.slice(0, mid));
let right = mergeSort(arr.slice(mid));
return merge(left, right);
}
function merge(left, right){
let result = [];
let i = 0, j = 0;
while(i < left.length && j < right.length){
if(left[i] < right[j]){
result.push(left[i]);
i++;
} else {
result.push(right[j]);
j++;
}
}
return result.concat(left.slice(i)).
concat(right.slice(j));
}
👉 Time: O(n log n) (fast)
💡 Simple idea:
Selection → find smallest
Insertion → place correctly
Merge → divide and combine
👉 Uses Divide & Conquer like Merge Sort
Steps:
Pick a pivot
Place smaller values on left, bigger on right
Recursively sort left and right
Example:
[5, 3, 8, 4, 2]
Pivot = 5
Left: [3,4,2], Right: [8]
Sort Left → [2,3,4]
Combine → [2,3,4,5,8]
Code:
function quickSort(arr){
if(arr.length <= 1) return arr;
let pivot = arr[arr.length - 1];
let left = [], right = [];
for(let i = 0; i < arr.length - 1; i++){
if(arr[i] < pivot) left.push(arr[i]);
else right.push(arr[i]);
}
return [...quickSort(left), pivot, ...quickSort(right)];
}
👉 Time: O(n log n) average, O(n²) worst
💡 Very fast in practice
Recursion = function calling itself
Important rules:
Base case → stop condition
Recursive call → keep going
Example: Factorial
function factorial(n){
if(n === 0) return 1;
return n * factorial(n - 1);
}
Factorial of 5 → 5 * 4 * 3 * 2 * 1 = 120
Common Recursion Patterns:
Counting / Summing
Traversing arrays
Tree traversal
Divide & Conquer
Fibonacci:
0, 1, 1, 2, 3, 5, 8, ...
Recursive Code:
function fib(n){
if(n <= 1) return n;
return fib(n - 1) + fib(n - 2);
}
💡 Simple idea:
Recursion = break big problem into smaller ones
Greedy Algorithm = always pick the best choice at the current step.
Example: Coin Change Problem
Coins: 25, 10, 5, 1
Amount: 41
Steps:
Take 25 → Remaining 16
Take 10 → Remaining 6
Take 5 → Remaining 1
Take 1 → Done
💡 Simple and fast, but not always optimal for all problems.
Problem: Pick items to maximize value
Each item has weight and value
Can take fraction of item
Algorithm:
Sort items by value/weight ratio
Pick items starting from highest ratio until full
Code (Simplified):
function fractionalKnapsack(items, W){
items.sort((a,b) => b.value/a.weight - a.value/b.weight);
let total = 0;
for(let item of items){
if(W >= item.weight){
W -= item.weight;
total += item.value;
} else {
total += item.value * (W/item.weight);
break;
}
}
return total;
}
Dynamic Programming = solve once, store result, reuse
Used when a problem has:
Overlapping subproblems
Optimal substructure
Example: Fibonacci Sequence
Recursive version = slow
DP version = fast (memoization)
DP Example (Fibonacci with Memoization)
let memo = {};
function fib(n){
if(n in memo) return memo[n];
if(n <= 1) return n;
memo[n] = fib(n-1) + fib(n-2);
return memo[n];
}
💡 Now fib(50) runs instantly instead of very slow recursion.
Backtracking = try all possibilities but undo if wrong
Idea:
Go forward → if it fails → go back → try another path
Example: Maze problem
Go through paths
Dead end → backtrack
Problem: Place N queens on N×N chessboard so no two queens attack each other.
Steps:
Place queen in first row
Move to next row
If safe → continue
If not safe → backtrack
💡 Used in puzzles, combinatorics, and constraint problems
Code (Simplified Pseudo-JS):
You can Check Example in it's picture!!!
Practice problems:
Reverse a string
Sum of array elements
Factorial
Fibonacci
Tree traversal
💡 Key idea:
Solve big problem → break into small problem → combine result
👉 BFS = visit nodes level by level
Uses Queue
Starts from a node and explores neighbors first
Example:
A → B → C → D
Code:
function bfs(graph, start){
let queue = [start];
let visited = new Set();
while(queue.length > 0){
let node = queue.shift();
if(!visited.has(node)){
console.log(node);
visited.add(node);
for(let neighbor of graph[node]){
queue.push(neighbor);
}
}
}
}
💡 Used in:
Shortest path (unweighted)
Social networks
👉 DFS = go deep first, then back
Uses Stack (or recursion)
Example:
A → B → D → C
Code:
function dfs(graph, node, visited = new Set()){
if(visited.has(node)) return;
console.log(node);
visited.add(node);
for(let neighbor of graph[node]){
dfs(graph, neighbor, visited);
}
}
💡 Used in:
Path finding
Cycle detection
👉 Finds shortest path in weighted graph
Example:
Cities with distances
Steps:
Start from source
Pick smallest distance node
Update neighbors
Repeat
Simple Idea:
Always choose minimum distance
💡 Used in:
Google Maps
Network routing
A string is just text:
"hello"
Common problems:
Reverse a string
Check palindrome
Count characters
Find substring
Example: Reverse String
function reverse(str){
return str.split('').reverse().join('');
}
Example: Palindrome Check
function isPalindrome(str){
return str === str.split('').reverse().join('');
}
💡 Used in:
Search engines
Text processing
Validation
👉 Used for arrays & strings
Idea:
Use a “window” and move it step by step
Avoid re-calculating again and again
Example: Max Sum of Subarray
function maxSum(arr, k){
let sum = 0;
for(let i = 0; i < k; i++){
sum += arr[i];
}
let max = sum;
for(let i = k; i < arr.length; i++){
sum += arr[i] - arr[i - k];
max = Math.max(max, sum);
}
return max;
}
💡 Much faster than checking all subarrays
👉 Use two indexes to solve problems
Example:
Find pair with sum = target
function twoSum(arr, target){
let left = 0;
let right = arr.length - 1;
while(left < right){
let sum = arr[left] + arr[right];
if(sum === target) return [left, right];
else if(sum < target) left++;
else right--;
}
}
💡 Works best on sorted arrays
👉 Store cumulative sums to answer queries fast
Example:
let arr = [1,2,3,4];
let prefix = [];
prefix[0] = arr[0];
for(let i = 1; i < arr.length; i++){
prefix[i] = prefix[i-1] + arr[i];
}
💡 Now you can get sum of any range quickly
👉 Work with binary (0 and 1)
Example:
5 = 101
3 = 011
AND (&)
5 & 3 = 1
💡 Used in:
Optimization
Competitive programming
Now the most important step:
👉 Practice = real skill
Start with:
Easy:
Reverse array
Find max/min
Palindrome check
Linear search
Medium:
Two Sum
Sliding window problems
Binary search problems
Hard:
Tree problems
Graph traversal
Dynamic Programming
💡 Rule:
👉 Don’t just read — solve by yourself
When you see a problem:
Step 1: Understand problem
👉 What is input? What is output?
Step 2: Think simple solution
👉 Even if slow (brute force)
Step 3: Optimize
👉 Use:
Binary Search
Sliding Window
Hash Table
DP
💡 Always go:
Simple → Better → Best
What companies expect:
Clear thinking
Clean code
Problem solving
Good understanding of basics
Focus topics:
Arrays & Strings
Linked List
Trees
Graphs
Recursion & DP
Tips:
Practice daily (even 1–2 problems)
Explain your thinking
Don’t panic in interview
A Data Structure is a way to store and organize data so that it can be accessed and modified efficiently.
An Algorithm is a step-by-step procedure or formula for solving a problem.
A Stack is a linear data structure which follows LIFO (Last In First Out) principle.
A Queue is a linear data structure which follows FIFO (First In First Out) principle.
A Linked List is a linear data structure where elements are stored in nodes connected via pointers.
An Array is a collection of elements stored at contiguous memory locations.
A Binary Tree is a tree data structure in which each node has at most two children.
A BST is a binary tree where the left child contains values less than the parent node and the right child contains values greater than the parent node.
A Graph is a non-linear data structure consisting of nodes (vertices) connected by edges.
DFS is a graph traversal algorithm that explores as far as possible along each branch before backtracking.
BFS is a graph traversal algorithm that explores all neighbors of a node before moving to the next level.
A Heap is a special tree-based data structure that satisfies the heap property: max-heap or min-heap.
A Priority Queue is an abstract data type where each element has a priority and elements with higher priority are served first.
A Hash Table is a data structure that maps keys to values using a hash function for fast access.
A Circular Queue is a linear data structure in which the last position is connected back to the first position to make a circle.
Recursion is a technique where a function calls itself to solve smaller instances of a problem.
Linear data structures store elements sequentially (e.g., array, stack, queue). Non-linear structures do not follow a sequence (e.g., tree, graph).
A Doubly Linked List is a linked list where each node points to both its previous and next node.
A Singly Linked List is a linked list where each node points only to the next node.
A Dynamic Array is an array that can grow or shrink in size during program execution.
Stack Overflow occurs when there is no more space in the stack for new elements, often due to infinite recursion.
A Deque (Double Ended Queue) allows insertion and deletion at both ends.
Linear Search is a search algorithm that checks each element of a list sequentially until the desired element is found.
Binary Search is a search algorithm that works on sorted arrays by repeatedly dividing the search interval in half.
Merge Sort is a divide-and-conquer sorting algorithm that divides the array into halves, sorts them, and merges them back.
Quick Sort is a divide-and-conquer sorting algorithm that selects a pivot and partitions the array around the pivot.
Bubble Sort is a simple sorting algorithm that repeatedly swaps adjacent elements if they are in the wrong order.
Selection Sort repeatedly selects the minimum element from the unsorted part and moves it to the sorted part.
Insertion Sort builds the final sorted array one element at a time by inserting elements at the correct position.
Tree Traversal is the process of visiting all the nodes in a tree in a specific order (e.g., inorder, preorder, postorder).
Graph Traversal is visiting all nodes in a graph systematically using algorithms like BFS or DFS.
An Adjacency Matrix is a 2D array used to represent a graph where rows and columns represent nodes.
An Adjacency List represents a graph as an array of lists where each list contains neighbors of a node.
A Sparse Graph has relatively few edges compared to the maximum possible edges.
A Dense Graph has many edges, close to the maximum possible edges.
A Directed Graph has edges with direction, indicating the connection from one node to another.
An Undirected Graph has edges without direction, meaning connections are bidirectional.
A Cycle is a path in a graph that starts and ends at the same vertex.
A Connected Graph is a graph where there is a path between every pair of vertices.
A Disconnected Graph has at least two vertices that are not connected by a path.
A Weighted Graph is a graph where each edge has a numerical weight or cost.
An Unweighted Graph is a graph where all edges are considered equal (no weights).
An MST of a graph is a subset of edges that connects all vertices with minimum total edge weight.
Dijkstra’s Algorithm finds the shortest path from a source vertex to all other vertices in a weighted graph.
Bellman-Ford Algorithm finds the shortest paths from a single source vertex to all other vertices, even with negative weights.
Topological Sort is a linear ordering of vertices in a directed acyclic graph (DAG) such that for every edge u → v, u comes before v.
A Hash Function maps input data to a fixed-size value, often used in hash tables.
A Collision occurs when two different keys produce the same hash value.
Chaining is a technique to handle collisions by storing multiple elements in a linked list at the same hash index.
Open Addressing resolves collisions by finding another empty slot in the hash table using probing techniques.
Stack follows LIFO (Last In First Out) whereas Queue follows FIFO (First In First Out).
Arrays use contiguous memory and allow fast index access. Linked Lists use pointers, allow dynamic memory allocation, but slower access.
A BST is a binary tree where the left child is less than the parent and the right child is greater. It allows efficient searching, insertion, and deletion.
BFS explores neighbors level by level using a queue; DFS explores as deep as possible using a stack or recursion.
A Heap is a special tree-based structure that satisfies the heap property: max-heap (parent ≥ children) or min-heap (parent ≤ children).
A Hash Table maps keys to values using a hash function for fast insertion, deletion, and lookup.
Linear search checks elements sequentially (O(n)). Binary search works on sorted arrays, dividing the search space (O(log n)).
Recursion is a function calling itself to solve smaller instances of a problem. It is used in tree traversal, divide & conquer algorithms, and backtracking.
Singly Linked List nodes point only to the next node. Doubly Linked List nodes point to both previous and next nodes.
A Circular Queue connects the last element back to the first, allowing efficient use of memory for insertion and deletion.
A Graph is a collection of vertices connected by edges, which can be directed or undirected, weighted or unweighted.
A Tree is an acyclic connected graph with hierarchical structure. A Graph can have cycles and arbitrary connections.
Topological sorting is a linear ordering of vertices in a DAG such that for every directed edge u→v, u comes before v.
MST is a subset of edges in a weighted graph connecting all vertices with the minimum total weight.
Dijkstra’s algorithm finds the shortest path from a source vertex to all other vertices in a weighted graph with non-negative weights.
DFS is a traversal strategy. Backtracking uses DFS along with undoing choices to solve problems like puzzles, N-Queens, and combinatorial search.
A Priority Queue is a queue where elements with higher priority are dequeued before elements with lower priority.
Merge Sort divides and merges arrays, stable and O(n log n). Quick Sort uses a pivot to partition arrays, generally faster but unstable.
A Cycle is a path that starts and ends at the same vertex in a graph.
Sparse Graph has few edges relative to vertices; Dense Graph has edges close to the maximum possible.
An Adjacency Matrix is a 2D array representation of a graph, where cell (i,j) indicates the edge between vertices i and j.
An Adjacency List represents a graph as an array of lists, where each list contains neighbors of a vertex.
A Hash Collision occurs when two different keys hash to the same index in a hash table.
Chaining handles collisions by storing multiple elements at the same hash index using a linked list.
Open Addressing resolves collisions by finding the next available slot in the hash table using probing.
A Balanced Tree maintains minimal height to optimize search, insertion, and deletion operations.
BFS is a graph traversal algorithm. Level Order Traversal is BFS applied specifically to a tree structure.
Recursion internally uses a call stack to track function calls. Stack is an explicit data structure for LIFO operations.
DP is an optimization technique to solve problems by storing results of overlapping subproblems to avoid recomputation.
A Greedy Algorithm makes the locally optimal choice at each step, hoping to find the global optimum.
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

 (1).png)
 (1).png)
.png)
.png)
.png)
.png)
.png)
.png)
 (1).png)
.png)
.png)
 (1).png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
 (1).png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
 (1).png)
.png)
.png)
 (1).png)
 (1).png)
.png)
 (1).png)
.png)
.png)
-Intro (1).png)
 (1).png)
 (1).png)
 (1).png)
.png)
.png)
.png)
.png)
.png)
.png)
 (1).png)
 (1).png)
.png)
.png)
.png)
.png){kind=link}
 (1).png){kind=link}